



There’s a version of your website that humans see and a version that AI crawlers see. For most businesses, these two versions are very different – and not in a good way.
A site can look polished, load reasonably fast, and rank on page one of Google, while simultaneously being almost unreadable to the AI crawlers that determine whether your brand appears in ChatGPT answers, Google AI Overviews, Perplexity results, and Claude responses. The problem isn’t your design. It’s what’s underneath it.
Understanding what AI crawlers are actually doing when they visit a website, and what they need to find, is one of the most practical and underused advantages available to businesses right now.
The Scale of AI Crawling in 2026
AI crawlers are now a primary force shaping which content gets discovered and cited, making AI search visibility optimization essential for businesses that want to appear in ChatGPT and Google AI Overviews.
Analysis of 24.4 million HTTP requests across 69 websites between January and March 2026 found that ChatGPT’s retrieval crawler made 3.6 times more requests than Googlebot across the same network, according to research published by Search Engine Journal. When all AI-related crawlers were grouped together, they generated 213,477 requests versus 59,353 for all traditional search crawlers combined – a 3.6x gap driven by the scale and frequency of AI retrieval activity.
Cloudflare, which processes roughly 20% of all global web traffic, separately reported more than 50 billion AI crawler requests per day across its network in 2025. The volume is no longer marginal.
Training Crawlers vs Retrieval Crawlers – A Critical Distinction
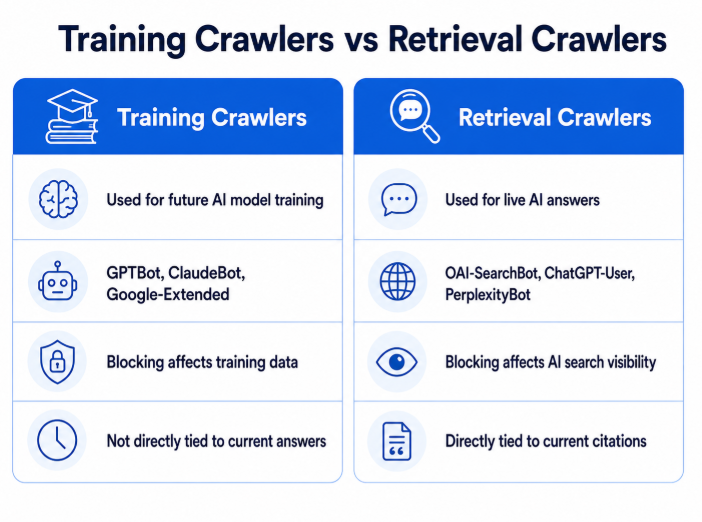
Not all AI crawlers do the same job and treating them as a single category leads to costly mistakes in robots.txt configuration.
As Search Engine Land’s comprehensive AI crawlers guide explains, AI crawlers divide into two fundamentally different categories.
Training crawlers collect content to improve AI models. OpenAI’s GPTBot, Anthropic’s ClaudeBot, and Google-Extended all fall into this category. These crawlers feed future model development. Blocking them keeps content out of training data but has no direct effect on current AI search visibility.
Retrieval crawlers fetch pages in real time to answer user queries. OpenAI’s OAI-SearchBot and ChatGPT-User crawl pages specifically to power ChatGPT’s live search results. PerplexityBot does the same for Perplexity answers. Blocking these crawlers is not neutral – it directly removes content from AI-generated answers today.
Many businesses block GPTBot assuming it controls ChatGPT visibility, without realising that OAI-SearchBot and ChatGPT-User are entirely separate crawlers with separate robots.txt controls. A site can block GPTBot successfully while still appearing in ChatGPT search results – and vice versa. OpenAI’s official crawler documentation explicitly confirms these are independent, separately controllable agents.
Checking which crawlers are currently allowed or blocked in a site’s robots.txt should be part of every technical SEO audit for AI search, and understanding what each one actually does, is one of the most immediate steps any business can take.
What AI Crawlers Can and Cannot Read
This is where most websites built before 2023 have a structural problem.
AI crawlers read HTML. They can parse clean, structured HTML reliably, extracting headings, body text, definitions, lists, schema markup, and JSON-LD structured data. What most of them cannot do is execute JavaScript.
As Search Engine Land’s guide to AI crawlers explains, most AI crawlers download JavaScript files as text but don’t run the code to render dynamic content. This means content that only appears after JavaScript executes, content loaded via AJAX calls, content rendered by React or Vue frameworks, content injected by tag managers, is invisible to most AI crawlers visiting the page.
This is a significant issue for sites built on modern JavaScript-heavy frameworks. The homepage or service page that looks complete and polished to a human visitor may return almost blank to an AI crawler if the content is rendered dynamically rather than served in the initial HTML response.
Google’s Search Central documentation on JavaScript SEO confirms this same constraint for Googlebot, which needs to queue JavaScript rendering as a second crawl pass; often much later than the initial fetch. For AI retrieval crawlers that don’t render JavaScript at all, the problem is permanent rather than delayed.
The practical fix is ensuring that critical content, service descriptions, key claims, FAQs, author information; is present in the initial HTML response. This doesn’t necessarily require abandoning JavaScript frameworks entirely, but it does require server-side rendering (SSR) or static site generation (SSG) for the pages that matter most for AI visibility.
What Crawlers Are Looking for Once They Can Read the Page
Once a crawler can access and parse a page’s content, it evaluates several things that determine whether the content is worth citing.
Structured data. Schema markup tells AI systems exactly what a page is about without ambiguity. Google’s structured data documentation explains how JSON-LD schema helps search systems understand entities, relationships, and content types. Article schema, Author schema, Organisation schema, and BreadcrumbList schema are the baseline for any page intended to earn AI citations. These don’t just help Google; they communicate the same clarity signals to every crawler that reads the page.
Answer-ready content structure. AI crawlers are specifically looking for extractable passages, making LLM-friendly content optimization an important ranking factor – content that answers a question in full, in a self-contained way, without requiring the surrounding paragraphs for context. Content written in long narrative blocks without clear subheadings gives crawlers much less to extract. Content structured around specific questions, with direct opening sentences and factual claims early in each section, gives crawlers multiple extractable passages per page.
Freshness signals. Publication dates, last-modified meta tags, and regular content updates all communicate recency. AI retrieval crawlers, particularly PerplexityBot which crawls at high frequency for real-time queries, prioritise recently updated content for time-sensitive questions. A page that hasn’t been touched in a year carries a freshness disadvantage regardless of its quality.
Crawl budget efficiency. Crawlers allocate a finite number of requests per site per crawl cycle. Sites with clean URL structures, no broken internal links, fast load times, and no redirect chains allow crawlers to index more pages per visit. Sites with accumulated technical debt, legacy redirects, duplicate content, slow server response times, waste crawl budget on overhead rather than content.
The Bing Index Point Most Businesses Miss
ChatGPT’s browsing mode retrieves pages from Bing’s search index, not Google’s. This means a site’s Google search performance has no direct bearing on whether ChatGPT can access its content through live retrieval.
If a site hasn’t been submitted to Bing Webmaster Tools or if Bing’s crawler has been blocked, that site’s content is not in the index ChatGPT browses. It’s structurally absent from ChatGPT’s live search regardless of how well it performs on Google.
Submitting a sitemap to Bing Webmaster Tools is one of the fastest ways to improve ChatGPT search visibility. and verifying that Bingbot is allowed in robots.txt takes under 30 minutes. It’s one of the fastest, most direct improvements available for ChatGPT visibility; and the majority of businesses haven’t done it.
A Useful Way to Think About It
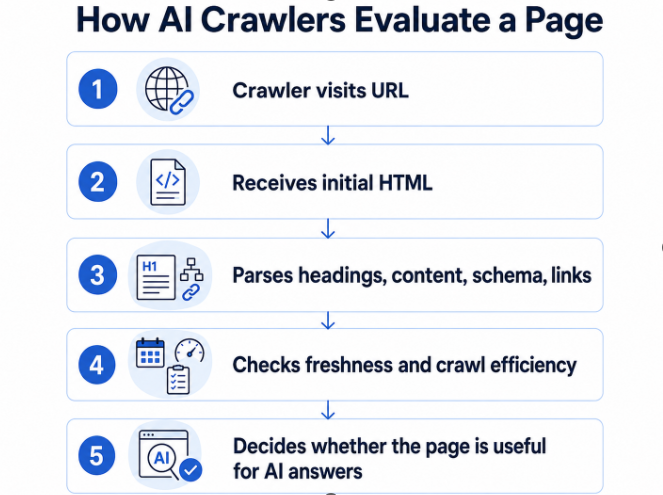 A website built in 2021 was designed for human visitors who scroll, click, and explore. An AI crawler doesn’t scroll. It sends an HTTP request, receives the initial HTML response, parses what’s there, and leaves. If the content it needed to cite was loaded dynamically after that initial response, the crawler never saw it.
A website built in 2021 was designed for human visitors who scroll, click, and explore. An AI crawler doesn’t scroll. It sends an HTTP request, receives the initial HTML response, parses what’s there, and leaves. If the content it needed to cite was loaded dynamically after that initial response, the crawler never saw it.
Redesigning for AI-first users doesn’t mean removing what works for humans. It means ensuring the content that matters is present in the HTML from the first request – structured clearly, marked up explicitly, and updated regularly.
The businesses that understand this distinction are building a crawlability advantage that compounds as AI search expands. The ones still building only for human browsers are solving for 2021.
What to rank on AI platforms?
Sudha Solutions helps businesses redesign and rebuild websites for AI-first users – combining UI/UX design, technical SEO, and AI visibility into one structured process. Based in India, working with brands globally. Contact us TODAY!
1. How can I check if AI crawlers are visiting my website?
You can monitor your server logs or website analytics platform to identify requests from AI crawlers such as GPTBot, OAI-SearchBot, ChatGPT-User, ClaudeBot, Claude-SearchBot, PerplexityBot, and Google-Extended. Server log analysis provides the most accurate view of which crawlers are accessing your site, how frequently they visit, and which pages they crawl.
2. Does blocking AI crawlers affect my Google search rankings?
No. Blocking AI-specific crawlers such as GPTBot or ClaudeBot does not directly impact your rankings in Google Search because they are separate from traditional search engine crawlers like Googlebot. However, blocking retrieval crawlers can reduce your visibility in AI-generated answers on platforms such as ChatGPT and Perplexity.
3. How often do AI retrieval crawlers revisit websites?
The frequency depends on the platform and the popularity of your website. High-authority websites and pages that are updated regularly tend to be crawled more often. For time-sensitive content such as news, product updates, or industry announcements, some AI retrieval crawlers may revisit pages multiple times a day, while less active websites may be crawled much less frequently.
4. Can AI crawlers read content that is behind a login or paywall?
In most cases, no. AI crawlers can only access content that is publicly available unless they are specifically authorised to access restricted areas. Content hidden behind login pages, membership portals, or paywalls is generally inaccessible to AI retrieval systems and therefore unlikely to appear in AI-generated responses.
5. Should every page on my website be optimised for AI crawlers?
Not necessarily. Focus first on high-value pages such as your homepage, service pages, product pages, pricing pages, knowledge base, blog articles, and FAQs. These are the pages most likely to be cited by AI systems when answering user queries. Supporting pages can be optimised over time as part of an ongoing AI SEO strategy.